on
Final Prediction
This blog is part of a series related to Gov 1347: Election Analytics, a course at Harvard University taught by Professor Ryan D. Enos.
Introduction
This post has been a long time coming. A culmination of all of my analytical work and experimentation with R this semester, this post will describe and evaluate my final predictive model for the 2022 Election.
For the last ten weeks, I have been building models to try to predict the election, using new dependent variables as we study them. After many different experiments and references to academic work, I chose the model that I will evaluate in this post, predicting nationwide seat share for each party.
Model Justification and Formula
After seeing how many different datasets and variables interact in a model, my final bit of inspiration came rather recently. In class last week, we read a series of articles about forecasting the 2018 midterms, evaluating their skill in presenting information to their reader. One of the articles, by Alan I. Abramowitz, described a model with very high statistical significance that predicted solely on three dependent variables: the number of seats a party held before the election, whether the president’s party was Democrat or Republican, and the generic ballot lead or deficit of the party.
I have been having some trouble throughout the semester with my models becoming overly complicated with too many variables and not enough data, so I used similar variables in my model, adding in GDP and mimicking Abramowitz’s formula for both parties, not just Republicans like he did in 2018.
In order to create a dataset to fit these needs, I started with historical data of nationwide vote and seat share. I also used a dataset of generic ballot results, I then filtered that data down to only polls after September 1st in order to get results closer to the election. I joined the historical data and the generic ballot data, and created variables for the generic ballot differences. Finally, I joined in GDP data and created two sets of data, one of all election years and one of only midterm election years.
I decided to use a simple linear model. I felt that the purpose of this week’s exercise was presentation and more complex models are much harder to understand on a widespread basis. Linear models convey information more simply and require fewer mathematical tricks to get to relatively similar results.
My model formula to find the seat share looked like the following, and I swapped out the party and dataset accordingly, ending up with two different types of model and one set for each party.
lm(PARTY_seats ~ PARTYballotdif + presparty + PARTY_seats_before + GDP_growth_pct, data = ELECTIONdata)
Coefficients

These are quite promising results. Every variable is statistically significant at the 5% significance level except for GDP, and both the generic ballot and number of seats held before the election are significant at the 1% level. The adjusted r-squareds are all strong in the mid 80s, at .861 for Democrats and .865 for Republicans when we look at the data for all elections.
When interpreting the coefficients, both generic ballot lead/deficit and seats before the election seem to change at similar rates for both parties. For every additional point lead in the generic ballot, the corresponding party is projected to gain about two and half seats in congress. For every additional seat held before the election, the party is projected to gain about a third of a seat.
The coefficient of president’s party reflects the concept of incumbent presidents’ parties being punished, particularly during midterms. In coding the variable, I designated +1 to Democratic presidents and 0 to Republican presidents. This conveys through the coefficients that if the president is a Democrat, the party is expected to lose 15 seats. In midterm years, this is exacerbated to 24 seats.
Finally, GDP growth is a bit wild. First, the only statistically significant coefficient for GDP is for Democrats in all election years. It indicates that for every additional percentage point of GDP growth, the Democrats lose 1.5 seats in the House. This doesn’t necessarily make sense given the literature that we have read and the results of my model earlier this semester that was solely based on GDP. Given the statistical insignificance of the other GDP coefficients, this variable should not be considered helpful.
Model Validation
In-Sample Fit
To evaluate my model, there are two types of testing we can conduct, in-sample fit and out-of-sample fit. In-sample fit uses the data we already have by looking at the r-squareds and comparing the in-sample error, defined as how often a prediction on historical data matches the actual historical result. I examined the r-squareds of my model and found that they are relatively strong, ranging around .86. To compare the in-sample error, I graphed historical results versus predictions for each model.
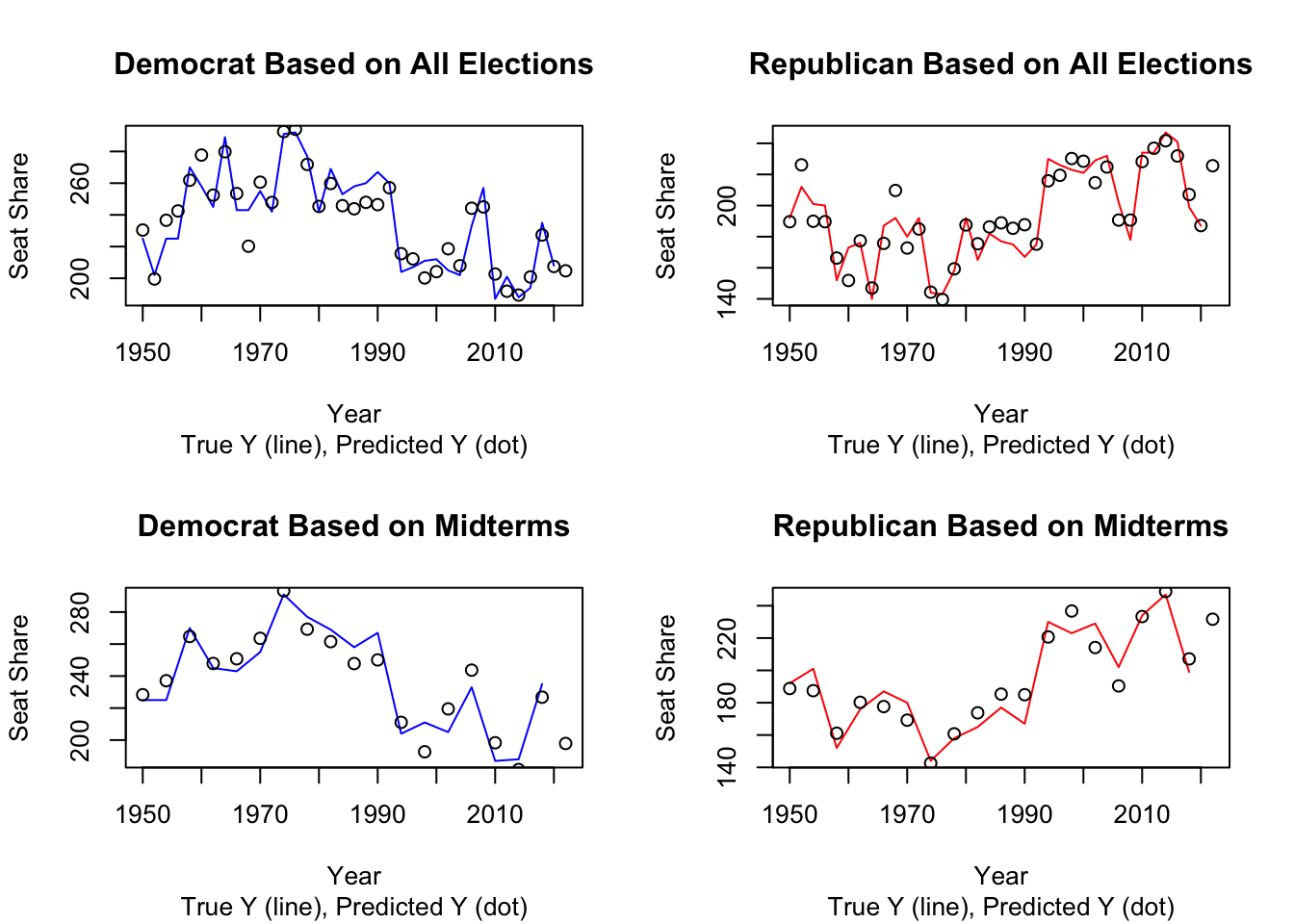
## [1] 10.52686## [1] 10.04894## [1] 9.956888## [1] 9.653612Based on the in-sample error graphs, the models containing on more data points, i.e. all of the elections instead of just midterms, seem to hit more historical data points and are more trustworthy. Afterwards, I calculated the mean squared error, a numerical summary of the difference between historical data and prediction, for each model. They all ended up around 10, so the models should be relatively comparable.
Out-of-Sample Fit
Out-of-sample fit tests are very similar to in-sample fit tests except that we withhold one historical observation from the data set in order to try to predict its result.
## 35
## -8.733373## 35
## 7.591793## 18
## -10.12312## 18
## 9.224524The numbers above represent the predicted value minus the true value for each model. This out-of-sample testing reveals that, for Democrats, the models underpredict the results, making the true value larger than the predicted value and yielding the negative numbers. For Republicans, the models overpredict the results in the opposite phenomenon. This is something to consider when it comes time to decide which model to choose for my final prediction because if I have a choice, the model with closer, less dramatic differences might be more correct.
Prediction Intervals and Uncertainty
## Model Fit lwr upr
## 1 Dem All Elections 204.7144 180.6889 228.7399
## 2 Rep All Elections 225.5925 202.6436 248.5414
## 3 Dem Midterms 197.8879 169.8948 225.8811
## 4 Rep Midterms 231.6727 204.5896 258.7558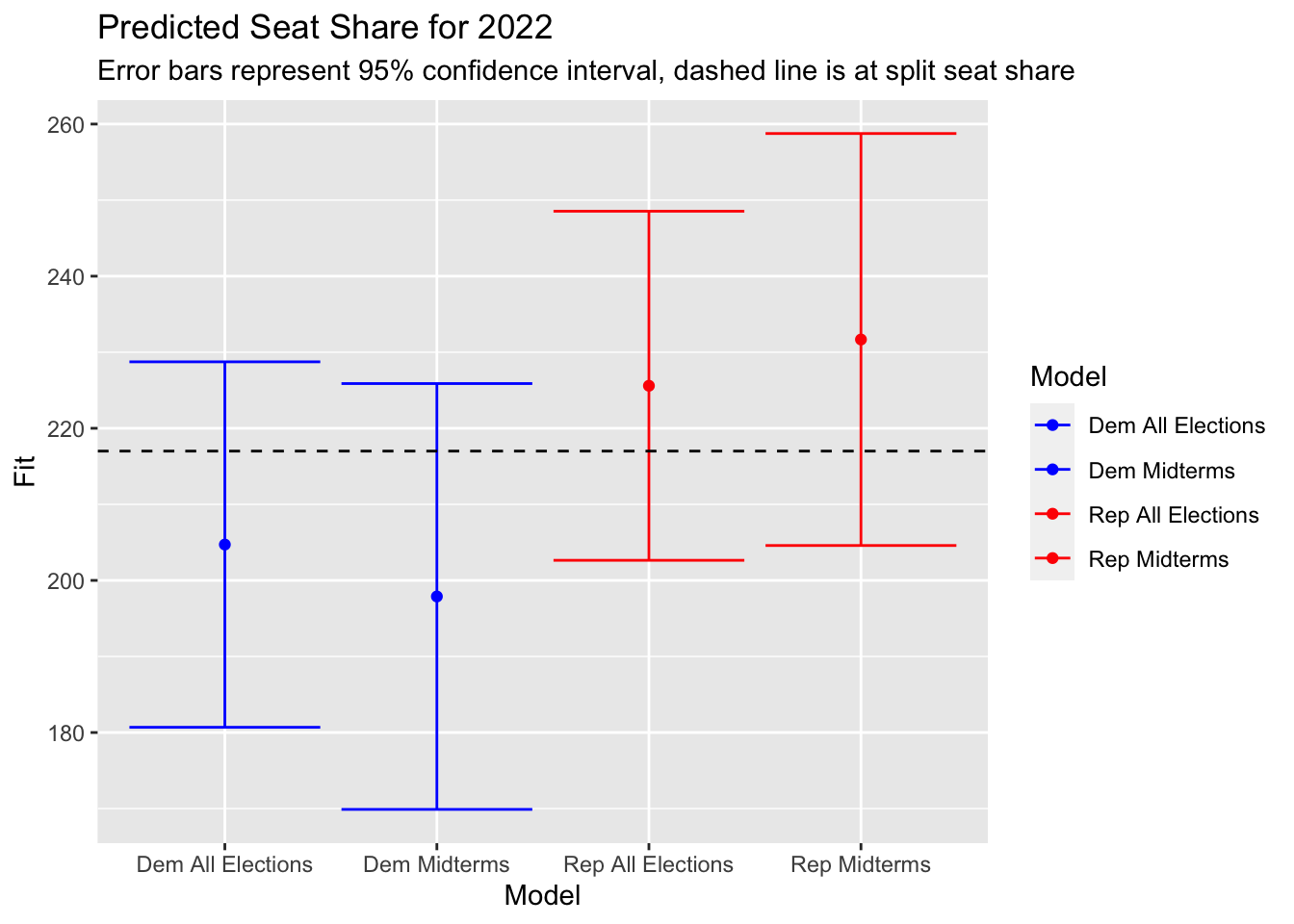 This graph depicts the fit, lower and upper bounds of each model’s prediction as shown in the table immediately before. These are relatively wide intervals of prediction. As a result, no matter the accuracy of the model, there is still enough overlap of the Democratic and Republican intervals that the party holding a majority of seats could flip.
This graph depicts the fit, lower and upper bounds of each model’s prediction as shown in the table immediately before. These are relatively wide intervals of prediction. As a result, no matter the accuracy of the model, there is still enough overlap of the Democratic and Republican intervals that the party holding a majority of seats could flip.
Final Prediction and Conclusion
Based on all of the investigations I have just completed regarding the accuracy of my models, I have decided to use the models based on all of the historical election data, not just midterms. Not only does that model have a smaller interval of prediction but it performed better on the out-of-sample fit test. While the adjusted r-squareds were also higher, it was by such a small amount (0.003) that it seems insignificant. They also had marginally smaller residual standard errors. Overall, I believe that the predictions that have more training data are more reliable.
Because I used separate models for Democrats and Republicans, their predicted seat totals do not add up to 435. In order to reach that number for our class predictions, I will rely on the Republican models and calculate Democratic seat share using simple subtraction, leading to a result of 210 seats for the Democrats and 225 seats for the Republicans. When using the fitted values from both my Republican and Democrat models, however, I predict that the Democratic party will win 205 seats and the Republican party will win 225 seats in the 2022 midterms.
Just because my final predictions are in doesn’t mean that this is my last blog post. I’ll be back for a reflection on the election results and the quality of my model soon!